How does apriori work? With the help of these association rule, it determines how strongly or how weakly two objects are connected. Apriori Algorithm in Machine Learning.
I will first explain this problem with an example. Datasets contains integers (=0) separated by spaces, one transaction by line, e.
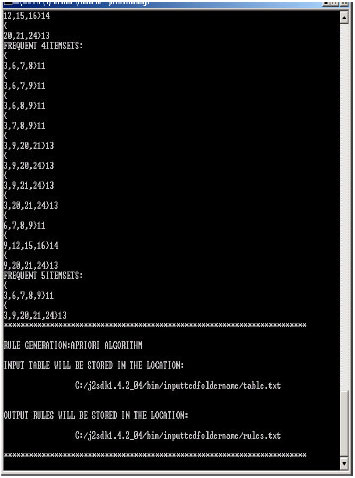
Size of step M for the DIC algorithm. Consists of four lines. Any item set is said to be frequent if support for that item set is greater than minimum support threshold. The result is we get frequent item sets i. This algorithm is generally applied to transactional databases i. Other algorithms are designed for finding association rules in data having no transactions (Winepi and Minepi), or having no timestamps (DNA sequencing).
See full list on codeproject.
The whole point of the algorithm (and data mining, in general) is to extract useful information from large amounts of data. For example, the information that a customer who purchases a keyboard also tends to buy a mouse at the same time is acquired from the association rule below: Support: The percentage of task-relevant data transactions for which the pattern is true. Itearticle in the basket.
Itemset: a group of items purchased together in a single transaction. Closed Itemset: support of all parents are not equal to the support of the itemset. Maximal Itemset: all parents of that itemset must be infrequent. GitHub Gist: instantly share code, notes, and snippets. It implements an item, which consists of a text.
Iteratively reduces the minimum support until it finds the required number of rules with the given minimum confidence. The algorithm has an option to mine class association rules. It is adapted as explained in the second reference. It is based on the concept that a subset of a frequent itemset must also be a frequent itemset.
Frequent Itemset is an itemset whose support value is greater than a threshold value (support). Let’s say we have the following data of a store. This data mining technique follows the join and the prune steps iteratively until the most frequent itemset is achieved.
It proceeds by identifying the frequent individual items in the database and extending them to larger and larger item sets as long as those item sets appear sufficiently often in the database.
The most prominent practical application of the algorithm is to recommend products based on the products already present in the user’s cart. The following are top voted examples for showing how to use weka. These examples are extracted from open source projects. You can vote up the examples you like and your votes will be used in our system to generate more good examples. Bucket Fill Algorithm This is Simple java implementation of bucket fill algorithm.
It is an iterative algorithm that divides the unlabeled dataset into k different clusters in such a way that each dataset belongs only one group that has similar properties. It allows us to cluster the data into different groups and a convenient way to discover the categories of groups in the unlabeled dataset on its own without the need for any training. It is designed to work on the databases that contain transactions. It is sometimes referred to as “Market Basket Analysis”.
Each set of data has a number of items and is called a transaction. With more items and less support counts of item, it takes really long to figure out frequent items. Hence, optimisation can be done in programming using few approaches. Each and every algorithm has space complexity and time complexity.
Usually, you operate this algorithm on a database containing a large number of transactions. One such example is the items customers buy at a supermarket.